
Fair warning: this one is long, and it gets fairly technical. But I think this particular security discussion matters, now that LLM calls are starting to look more like infrastructure.
Calling an LLM Is a Data Exposure Decision
Most teams integrate LLMs the same way they integrate any API. You grab a key, wire up the endpoint, send a prompt, get a response. It works. The product ships. Then six months later someone asks:
“Wait, what data are we actually sending to that thing?”
That question is usually asked too late.
Calling an LLM is not just an API integration problem. Every prompt you send is a data decision. And as more enterprises move from hosted APIs toward distributed inference, self-hosted models, and AI agents that operate autonomously on your behalf, the security considerations around that decision get a lot more interesting.
This is my attempt to lay out what I think enterprise architects and developers actually need to think about here. I’m going to focus on a few things that I think are still underappreciated: the difference between encryption in transit and encryption in use, client-side tokenization as a practical privacy layer, what it actually means to trust whoever is on the other side of an inference call, and why agents raise the stakes on all of this considerably.
The Problem with “It’s Encrypted in Transit”
When you ask most teams about LLM data security, the answer you get is something like:
“We use HTTPS and our API keys are secrets.”
That is a fine start. But it does not address where the risk actually lives.
Encryption in transit protects your data while it’s moving over the wire. Encryption at rest protects your data sitting on disk or in a database. Neither of these protects your data while it’s being processed. When a GPU is running inference on your prompt, the prompt exists in plaintext in memory. The model has to see it to do anything useful with it.
This means the real question is not:
“Is the connection encrypted?”
It is:
“Who controls the machine where my prompt gets decrypted?”
If you’re calling OpenAI or Anthropic or another major hosted API, you’re trusting that provider’s infrastructure, access controls, employees, policies, and contractual commitments. That can be a perfectly reasonable trust decision for many workloads. Their security postures are generally strong, and they publish details about how they handle data.
But the threat model shifts when you start moving inference to:
- Self-hosted models on shared infrastructure
- Distributed inference platforms where GPU operators are third parties
- API aggregators like OpenRouter, where your prompt passes through an intermediary before reaching the provider that actually processes it
- Agent frameworks like OpenClaw or Hermes, where a long-running agent assembles context from memory, tools, and retrieved documents before making inference calls
- Fine-tuning pipelines that ingest your internal data
In all of these cases, you need a more precise mental model of where your data actually lives and who can see it.
The question is not just “is this endpoint trustworthy?”
The better question is:
“How many boundaries does my prompt cross before it gets processed, and what happens at each one?”
The Zones of Data Exposure
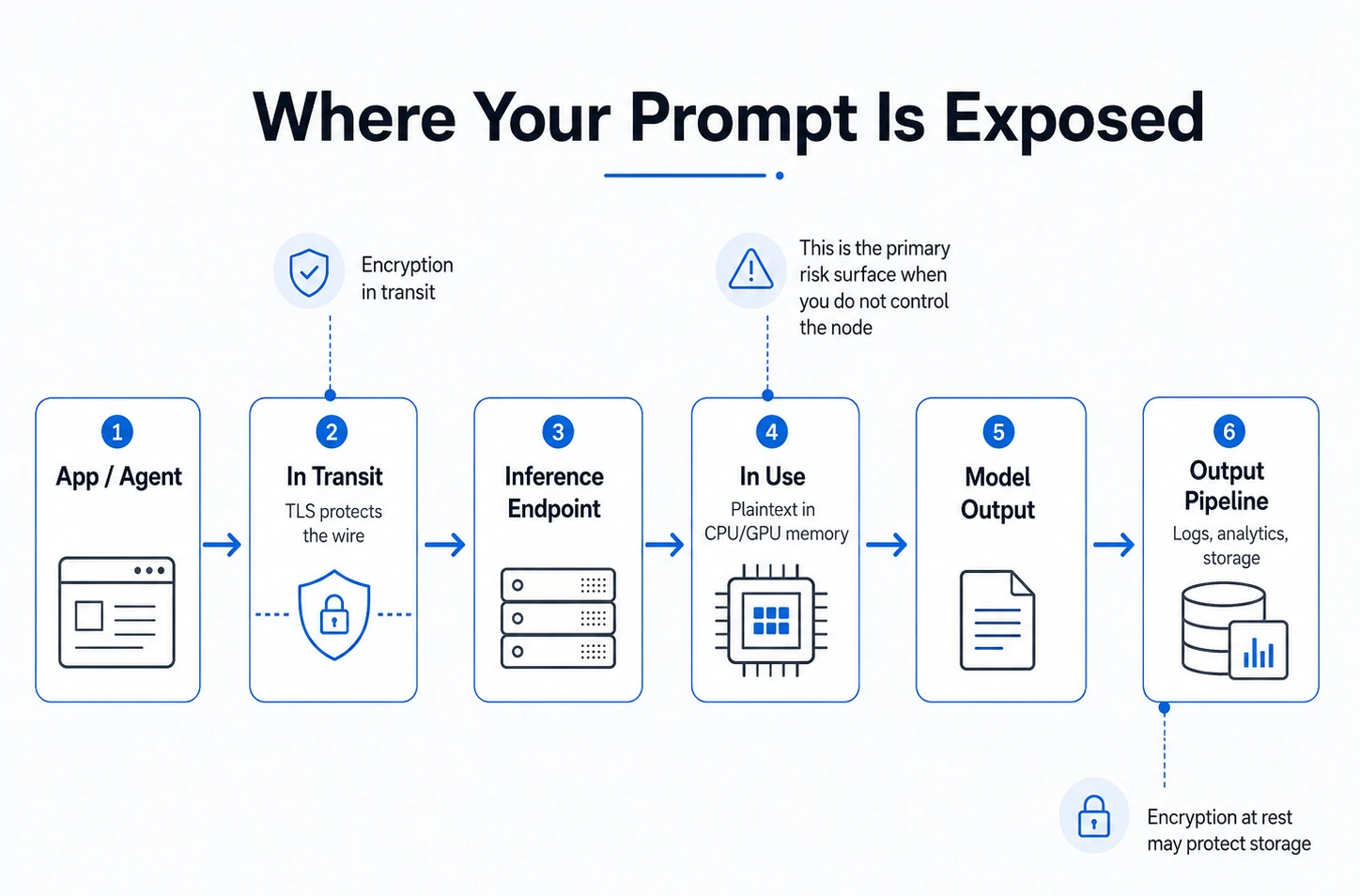
It’s useful to think about LLM data exposure in zones:
1. In transit: The prompt traveling from your app to the inference endpoint. TLS handles this. Standard practice.
2. At rest: Logs, saved conversations, fine-tuning datasets, embeddings. Standard encryption and access controls apply. Most teams understand this part reasonably well.
3. In use: The prompt decrypted in CPU or GPU memory during inference. This is where ordinary encryption stops working. The node running inference has to see the plaintext. If you don’t control the node, this is your primary risk surface.
4. In the output pipeline: The response traveling back to your app, and then any downstream processing, logging, analytics, or storage. This is often overlooked. Responses can contain PII or sensitive business data that was in the original prompt. If you log completions for debugging, those logs may contain exactly the data you were trying to protect.
Most security conversations about LLMs focus on zone one and gloss over zones three and four.
That’s where the interesting problems are.
Agents Make Everything Harder
A single stateless prompt has a limited blast radius. An autonomous agent is a different situation entirely.
Agent frameworks like OpenClaw and Hermes are increasingly how teams deploy long-running AI workloads. These agents maintain persistent memory across sessions, execute tools, access external APIs, browse the web, and manage files.
The context window of an active agent might include OAuth tokens injected for tool use, retrieved customer records, database connection strings, previous conversation history with sensitive content, and the outputs of tool calls that contain real data.
That is a much larger exposure surface than a one-shot prompt.
Most agent frameworks sit above the inference layer without a privacy abstraction between them. OpenClaw, for instance, has a well-designed gateway that handles routing, authentication, and session management, and that gateway never touches the model directly. That’s a good architectural principle. But the gateway doesn’t apply PII scrubbing before the inference call goes out.
Hermes has strong process isolation and container hardening, which protects the host from the agent, but does not by itself protect your data from the inference provider.
Both frameworks can route calls through services like OpenRouter, which is where things get layered in an interesting way.
OpenRouter by default does not log your prompts or completions. It stores request metadata: timestamps, model used, token counts, latency. Your conversation content is not retained unless you specifically opt into prompt logging. OpenRouter also has a Zero Data Retention setting that restricts routing to endpoints whose providers have made ZDR commitments.
But here’s the part most teams miss: when you send a request through OpenRouter, it routes that request to a downstream provider, and that provider processes your prompt under its own data retention policy. OpenRouter does not magically change what the provider stores. If your request goes to a provider with a 30-day abuse monitoring window, that window applies regardless of your OpenRouter settings.
OpenRouter displays the retention policy for each provider endpoint in its interface, which is genuinely useful, but it requires you to actually check the models and providers you’re using.
None of this is a criticism of OpenRouter. It’s a good product and the ZDR controls are real. The point is that “I use OpenRouter” is not itself a privacy posture.
The data retention question has two layers, not one, and the second layer depends on which provider backend actually handles your request.
For agent workloads where the context window may contain credentials or customer data, routing through any external inference provider should be a deliberate decision with explicit policy attached to it.
Client-Side Tokenization: The Practical First Layer
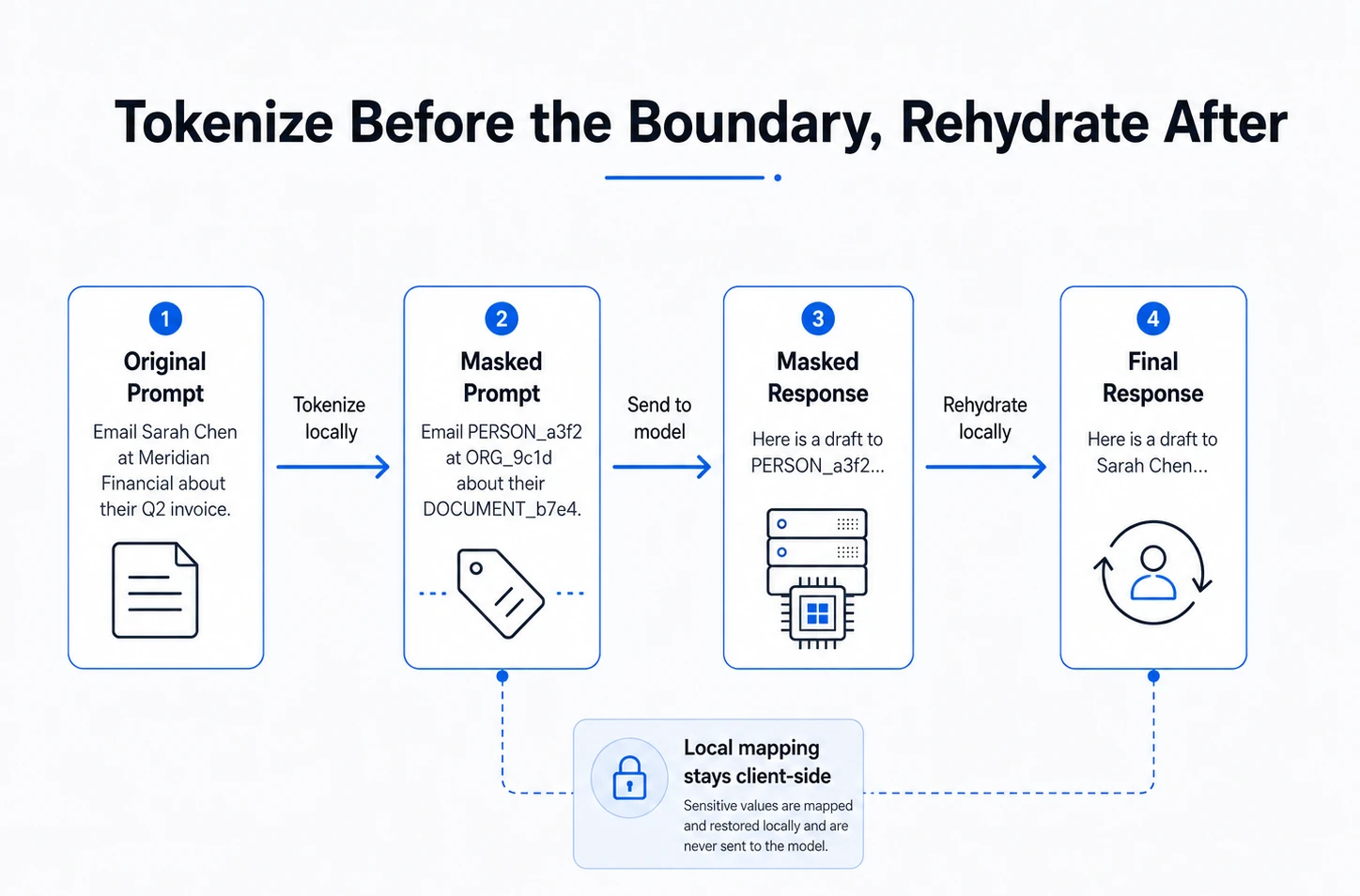
Here is a technique that I think is underused in enterprise deployments - LLM or otherwise: tokenize sensitive values before they leave your application.
The idea is straightforward. Before sending a prompt to any inference endpoint you don’t fully control, your application identifies sensitive entities and replaces them with placeholder tokens. The mapping stays local. The inference node sees the tokenized prompt. Your app gets the tokenized response back and rehydrates it by swapping tokens for original values.
A simple example:
Original prompt:
"Draft a response to Sarah Chen at Meridian Financial about their Q2 invoice."
Tokenized prompt sent to the model:
"Draft a response to PERSON_a3f2 at ORG_9c1d about their DOCUMENT_b7e4."
Local mapping, never sent to the model:
{
"PERSON_a3f2": "Sarah Chen",
"ORG_9c1d": "Meridian Financial",
"DOCUMENT_b7e4": "Q2 invoice"
}
The model gets enough context to do its job. The inference node never sees the real names, company, or document reference. When the response comes back, your app does a simple substitution.
This is not a cryptographic guarantee. If your token scheme is predictable, or the surrounding context gives too much away, a determined observer may still be able to infer things. But for many enterprise scenarios, tokenization meaningfully reduces exposure. It is especially useful when you’re routing lower-sensitivity workloads to distributed or third-party compute.
The key design principle is that the mapping table should stay client-side.
The moment you ship the mapping to an external service to do the rehydration, you’ve negated most of the benefit.
What Tools Exist for This Today
This space is more mature than I expected when I started digging in.
Microsoft Presidio is the most established open-source framework here. It’s a Python library with two main components: an analyzer that detects PII using NLP, regex, and named entity recognition, and an anonymizer that replaces detected entities according to configurable strategies. It includes many predefined entity types, including names, emails, phone numbers, credit card numbers, SSNs, addresses, and more. You can also add custom recognizers for internal account numbers or proprietary identifiers.
The detection quality can be quite good, especially when you back it with stronger NLP recognizers, but it still needs testing against your own data.
LiteLLM has a Presidio callback built in. If you’re already using LiteLLM as your proxy layer, you can add PII masking through configuration. The proxy can strip PII from outbound prompts and optionally restore tokens in responses.
PII Shield is a recent Microsoft Community Hub project that wraps Presidio in a FastAPI service with per-entity strategies, multi-tenant support, and reversible anonymization. Worth watching.
These are good tools. The detection problem is not unsolved.
The gap I kept coming back to was somewhere slightly different.
The Gap the Existing Stack Doesn’t Fill
There are good tools for detection. What I couldn’t find was the boring infrastructure piece I actually wanted: a transparent privacy layer at the inference call boundary itself.
Whether that boundary is a local Ollama instance, a llama.cpp server, a vLLM deployment, OpenRouter routing to a cloud provider, or a direct call to OpenAI or Anthropic, the same gap exists.
Something needs to sit between your agent or application and the endpoint, scrubbing the prompt before it leaves and restoring values when the response comes back.
You can build that layer yourself. Or you can wire together a multi-process stack and hope it works for your deployment.
LiteLLM plus Presidio is probably the most common attempt at closing this gap, and it’s functional, but it has real limitations worth understanding.
It can be a multi-process setup. You may be running LiteLLM, the Presidio analyzer service, and the Presidio anonymizer service as separate processes and coordinating their configs. For a developer deploying an agent on a small VPS, or running something like OpenClaw as a personal assistant, that is meaningful operational overhead.
Streaming is also still the awkward edge. Depending on the mode and provider path, response-side parsing may happen after the stream has already been delivered, which makes true streaming detokenization difficult. For non-streaming calls, that may be fine. For agent workloads where streaming is the default interaction pattern, it can become a real usability gap.
There’s also the question of persistence. Presidio’s anonymizer can use mappings for a request, but for a long-running agent that references the same entities across multiple inference calls in a session, you need a way to persist those mappings across calls without losing them between requests.
None of this is a criticism of Presidio. It’s an excellent library and the NER (Name-Entity Recognition) quality is significantly better than what you’d get from regex alone or from prompting a small local model.
The gap is in the infrastructure layer around it, not in the detection capability itself.
privox: A Transparent Proxy for the Gap

So I did what I seem to do now when a gap bothers me: I turned it into a small open-source project, with plenty of help from an AI coding agent.
The result is a Rust project called privox: a single-binary transparent proxy with an OpenAI-compatible API surface.
You point your agent or application at localhost:11435 instead of wherever it currently points — a local Ollama instance, llama.cpp, vLLM, OpenRouter, OpenAI, Anthropic, or anything else with an OpenAI-compatible interface — and tokenization and detokenization happen automatically without changing your agent or application code.
OpenClaw, Hermes, a custom Python app, a local model wrapper, a Claude Code-style workflow pointed at an OpenAI-compatible endpoint: if it speaks the OpenAI API format, it can sit behind privox.
The design has a few things I wanted but did not want to keep rebuilding in every project.
Streaming detokenization is first-class. The proxy handles tokens that span SSE chunk boundaries and forwards chunks as they arrive rather than buffering the entire stream.
The token-to-value mapping is stored in an encrypted local vault using SQLite and AES-256-GCM. Tokens are HMAC-keyed to the installation secret so the same entity gets the same token within an installation.
Detection is pluggable. The default backend is a Rust regex engine covering structured PII: emails, phone numbers, credit cards, IBANs, SINs, SSNs, API key patterns, and IP addresses. Optionally, you can point it at a local Ollama model for contextual NER, or at a locally running Presidio analyzer service for stronger detection quality.
When Presidio is configured, privox uses it only for detection and handles tokenization, detokenization, streaming, routing, and local vault storage itself. If the Presidio sidecar goes down, privox falls back to regex-only rather than failing the request.
The important thing to say about privox relative to Presidio is that it is not trying to replace Presidio’s detection capability. Presidio’s NER is better, supports more entity types, supports multiple languages, and has years of investment behind it.
What privox is trying to replace is the multi-process infrastructure glue you need to build around Presidio to get a working transparent proxy.
Presidio is the engine. Privox is the boring pipe around it. And when Presidio is available, privox can use it as the backend.
The obvious caveat: tokenization is only as good as detection. Regex catches structured secrets well. Presidio catches more contextual PII. Neither is magic. A proxy like this reduces exposure; it does not make unsafe data safe.
The project is early, but functional, and open source here:
🔗 github.com/jamie-agenticnorthlabs/privox
Not All Prompts Are Equal: Routing by Sensitivity

Once you are thinking about tokenization, the natural next question is where different types of prompts should be routed in the first place.
This applies whether you’re running a distributed GPU platform, routing agent calls through OpenRouter, or just deciding which workloads can use a shared inference endpoint and which need to stay local.
Not every inference job has the same risk profile.
A prompt to summarize generic marketing copy is fundamentally different from a prompt that includes customer financial records, health information, or credentials. Treating them the same way is a mistake.
A useful classification looks something like this:
| Sensitivity | Examples | Where It Should Run |
|---|---|---|
| Public | Generic content generation | Any approved inference endpoint |
| Low | Internal notes with no PII | Any approved endpoint |
| Masked | Business content after tokenization | Verified third-party nodes or hosted APIs |
| Sensitive | Health, legal, financial, HR data | Your infrastructure or trusted managed nodes only |
| Secrets-bearing | API keys, OAuth tokens, credentials | Never leaves your environment |
| Local-only | Maximum privacy requirement | On-device or self-hosted only |
The “secrets-bearing” category deserves special emphasis in the context of agents.
An autonomous agent’s context window might include OAuth tokens, database connection strings, or API keys injected to enable tool use. That context absolutely cannot be routed to third-party compute. If you’re building agents, you need explicit policy that secrets-bearing workloads stay on infrastructure you control.
Full stop.
This is also where the upstream config in a proxy like privox earns its keep. You point secrets-bearing workloads at a local endpoint and everything else at OpenRouter or whichever provider fits the sensitivity tier. The tokenization layer handles scrubbing regardless of destination, and the routing decision becomes a config choice rather than something baked into your agent’s logic.
The Trust Problem in Peer-to-Peer Inference
There’s a specific category of GPU compute worth understanding separately: peer-to-peer GPU marketplaces like Vast.ai and io.net, where individuals and small operators contribute their own hardware and you rent it by the hour.
These are real platforms with genuinely low prices. They are also the scenario where the privacy question gets most interesting.
I think this market is going to get larger. The economics are compelling for GPU owners: the shift away from crypto mining left a lot of consumer hardware looking for workloads, AI inference demand keeps growing, and the entry barrier for contributors keeps dropping as “connect and earn” platforms mature.
A home gamer with an RTX 4090 sitting idle overnight is exactly the kind of supply these networks are designed to make useful.
Today, most enterprises are not routing production workloads through peer-to-peer GPU marketplaces. Two or three years from now, there may be more polished versions of this model with easier onboarding, broader hardware support, and pricing that makes the tradeoff genuinely attractive for cost-sensitive inference.
Understanding the trust model now is the right time.
When you send an inference job to a platform like this, the machine processing it may be owned by someone you have no relationship with and cannot vet. The platform can set terms of service and may run monitoring infrastructure, but the physical hardware belongs to a third party.
The honest answer to “what can that node operator see?” is:
Potentially everything.
Even if the platform says “we encrypt in transit and don’t log,” the operator of the physical machine can, in principle, inspect memory, attach debuggers, dump logs, or snapshot the VM during inference. Promises and terms of service are not technical controls.
This is distinct from specialist GPU clouds like CoreWeave, RunPod, or Lambda Labs, which are centralized infrastructure businesses with their own hardware and more conventional enterprise privacy postures. The trust model there is closer to any cloud provider.
The peer-to-peer marketplace model is the scenario where the mitigations below actually matter.
There are several layers you can add to reduce exposure.
KYC and contracts: Require node operators to verify their identity, sign data handling agreements, and accept no-log commitments. This creates accountability, but not technical prevention. A verified bad actor is still a bad actor.
Runtime image signing: Require nodes to run only signed container images from a platform registry, with image hashes published. This narrows the attack surface, but it doesn’t prevent a malicious host from inspecting memory.
Route obfuscation: Strip origin identity from the job envelope so the node doesn’t know who the user is, what company they’re from, or what larger workflow the job belongs to. The node gets a job ID, a model name, a masked prompt, and a result slot. That’s it.
Traceable inference receipts: Generate audit records for every inference job that include hashes of the prompt and output, the node identity, the operator identity, the model hash, and the privacy tier. The receipt doesn’t store the raw content, but it provides evidence for dispute resolution, compliance, and billing. You can prove what ran where without exposing what was processed.
All of these are meaningful.
None of them are sufficient if you have a genuinely adversarial node operator.
The Only Strong Claim: Confidential Computing
If you’re using a peer-to-peer inference marketplace and actually need to be able to say “the node operator could not have seen this data,” there is only one technical architecture that supports that claim:
Remote attestation plus confidential computing plus controlled key release.
The pattern works like this:
- Your client tokenizes the prompt locally.
- Your client encrypts the tokenized prompt before sending it.
- The inference node starts a confidential execution environment.
- The node generates a signed attestation report proving what software it’s running, what firmware versions are present, and that debug mode is disabled.
- An attestation verifier checks that report against known-good measurements.
- A key broker releases the decryption key only if the attestation passes.
- The prompt is decrypted inside the confidential runtime.
- The model runs inference.
- The output is encrypted back to the client.
- The client decrypts and rehydrates locally.
The important property here is that the decryption key is not released unless the host can prove it’s running exactly the right software in exactly the right state.
A node operator who modifies the kernel, attaches a debugger, or runs a tampered runtime image should fail attestation and never receive the key.
That is a technical control, not a policy promise.
The catch is cost and complexity. This requires datacenter-grade confidential compute support, specialized hardware, and a mature attestation and key-release flow. NVIDIA H100-class hardware is the kind of world where this starts to become possible. You should not assume you can do this on a home gaming GPU.
A single-GPU setup with the full server infrastructure and hosting required for confidential inference can easily move into the several-hundred-thousand-dollar CAD range. Cloud rental for confidential GPU instances also runs higher than standard GPU rental.
That’s not the default checkbox.
That’s the expensive tier for workloads where you really do need the stronger claim.
What to Actually Do Today
Most teams are not building distributed GPU platforms.
They are building applications and deploying agents that make inference calls to hosted APIs, self-hosted models, aggregators like OpenRouter, and local model servers. They need a practical approach to data hygiene around those calls regardless of where the inference actually runs.
Here is what I’d recommend as a starting point.
Classify your prompts. Identify which of your LLM workflows include PII, sensitive business data, or anything credential-adjacent. You probably have fewer sensitive workflows than you think, but you need to know which ones they are.
Add tokenization to sensitive workflows. Use Presidio or a similar library to strip PII from prompts before they leave your application. Keep the mapping local. Rehydrate responses on your side. If you’re on Python and already using LiteLLM, the LiteLLM plus Presidio path may be the lowest friction. If you’re not on Python, or you need streaming detokenization, look at alternatives.
Put a proxy layer at the inference call boundary. A transparent proxy in front of your inference endpoint gives you a consistent place to enforce PII policies, log metadata without logging content, and swap model backends without touching agent code. This is especially valuable for agent deployments where the same agent might make dozens of inference calls in a single workflow, each carrying accumulated context. If you want something you can drop in today, privox is the project I built to fill exactly this gap. Point your agent at it instead of the upstream and tokenization happens automatically.
Audit your logs. If you’re logging LLM completions for debugging, you may be storing sensitive data you did not intend to store. Either stop logging raw completions or run them through the same scrubbing pipeline you apply to prompts.
Set explicit policy for agents. If you’re deploying autonomous agents, define which workloads can use external inference and which must stay local. Agents that have access to credentials, customer data, or browser control should run on infrastructure you control. This policy needs to be enforced in code, not just documented.
Check your OpenRouter provider routing. If you’re using OpenRouter, look at the provider data retention policies shown for the models you’re actually using. The OpenRouter-level ZDR setting and the provider-level retention policy are separate questions. Both matter.
Be honest with your users. If you’re building a product that routes user prompts to third-party inference, say so. Don’t describe distributed community compute as “private.” Say what it actually is: affordable inference with technical controls that reduce but do not eliminate exposure.
The Bigger Picture
LLMs are becoming infrastructure.
They’re moving from experimental tools into production systems that process real customer data, make real decisions, and operate with real credentials in real environments. Agents are accelerating that transition.
The enterprise security conversation around LLMs has been maturing, but it’s still catching up to where deployments actually are.
Encryption in transit is table stakes. The harder problems are in-use data exposure, trust in distributed compute, and the privacy properties of long-running agentic workflows that carry context across dozens of inference calls.
There are roughly three tiers of response to this problem, and they address different threat levels.
The first tier is tokenization at the inference call boundary. Strip sensitive values before the prompt leaves your environment, keep the mapping local, restore values on the way back. This is accessible today, it works against every inference endpoint regardless of who operates it, and the operational overhead can be low.
This is what privox is trying to make even lower: a transparent proxy that handles tokenization automatically. It does not protect you against a determined adversarial operator, but it meaningfully reduces exposure for many real workloads.
The second tier is provider selection and policy. Use hosted APIs with strong data handling commitments for sensitive workloads. Enforce Zero Data Retention at the OpenRouter level and check what the downstream provider actually does. Keep secrets-bearing agent workloads on infrastructure you control.
This costs nothing to implement beyond the discipline to actually do it.
The third tier is confidential computing: hardware-backed attestation, trusted execution environments, and controlled key release. This is where you can make a technical claim rather than a policy promise. It’s genuinely expensive and operationally complex, and it requires datacenter-grade hardware that most teams are not going to buy.
But as the peer-to-peer inference market matures and more workloads route through hardware you have no relationship with, the use cases for this tier are going to grow.
Most teams need tier one and tier two right now.
Tier three is worth understanding so you recognize when your threat model has crossed into it.
If you’re building something in this space or thinking through LLM data security in your org, I’d like to hear about it. I’m on Bluesky at @jamiebeach.bsky.social.
This article was written by Jamie, with the assistance of both ChatGPT 5.5 and Claude Sonnet 4.6. We did A LOT of back and forth. Images generated with ChatGPT.