The term “agentic workflow” gets used a lot right now, and I don’t think it means the same thing to everyone who uses it. Sometimes it means a Python script with an LLM call in the middle. Sometimes it means a fully autonomous system that pursues a goal across multiple steps, managing its own tools and memory. Sometimes it means everything in between.
That ambiguity isn’t necessarily a problem, new ideas often outpace the vocabulary we have for them. But I’ve found that the fuzziness makes it harder to design well. When “agentic” can mean almost anything, it’s difficult to ask the more useful question: where does the agent actually live in this system, and what is it doing there?
I’ve been building with AI for a couple of years now, using LLMs to accelerate coding, summarizing content, incorporating LLMs, TTS, and image generators into creative projects, building apps where AI is either a core or adjacent capability. But it’s only recently, in the last few months, that I’ve started thinking explicitly in terms of agents and agentic systems. Before that, I was just building things that worked. Content pipelines, dynamic integrations, chatbots, content analyzers. In retrospect, these were all probably agentic systems, but at the time, I wouldn’t have called them that.
I suspect that’s true for a lot of people working in this space right now (which is probably nearly all of us, at some level). The vocabulary is catching up to the practice. And now that the word “agent” is everywhere, it’s worth pausing to think more carefully about what it actually means in a system, not just as a label, but as a design decision. This post is an attempt to sketch that out.
It’s one framing, not the framing. But it’s maybe useful enough. At some point in the near future, I’m certain that O’Reilly will publish a book called “Agentic Systems Architecture” and it will be “the definitive text” on this topic. But until then, this is my take on how to think about where agents actually live in the systems we’re building.
Two Kinds of Execution
Before getting into patterns, it helps to be precise about deterministic versus non-deterministic execution, because that distinction is the fundamental axis along which agent systems are designed.
A deterministic system follows a predictable, inspectable execution path. You know what will run, in what order, and you can trace exactly what happened after the fact. A Python script that parses a CSV and writes to a database is deterministic. An automated workflow that fires when a webhook arrives and posts to Slack is deterministic. Even a pipeline that calls an LLM internally can be deterministic in character, if the orchestration, routing, and error handling are structured and auditable. These systems are traceable, cheap to run, and break loudly with traces you can actually read.
A non-deterministic system, an LLM at its core, doesn’t work that way. Given the same input, it may produce meaningfully different outputs. That’s not a bug, it’s the feature. It’s what allows a language model to interpret ambiguous instructions, reason across unstructured data, make judgment calls, and produce outputs that feel more like thinking than computation.
The catch is that this flexibility has a cost. Literally: every LLM call burns tokens, and tokens cost money and time. But also operationally: when something goes wrong in an agent loop, you can’t replay it deterministically. The execution path is opaque. Debugging is more like archaeology than reading a log file.
Both of these things are true simultaneously. The most effective systems I’ve built use both, and the interesting design question is exactly where each one lives.
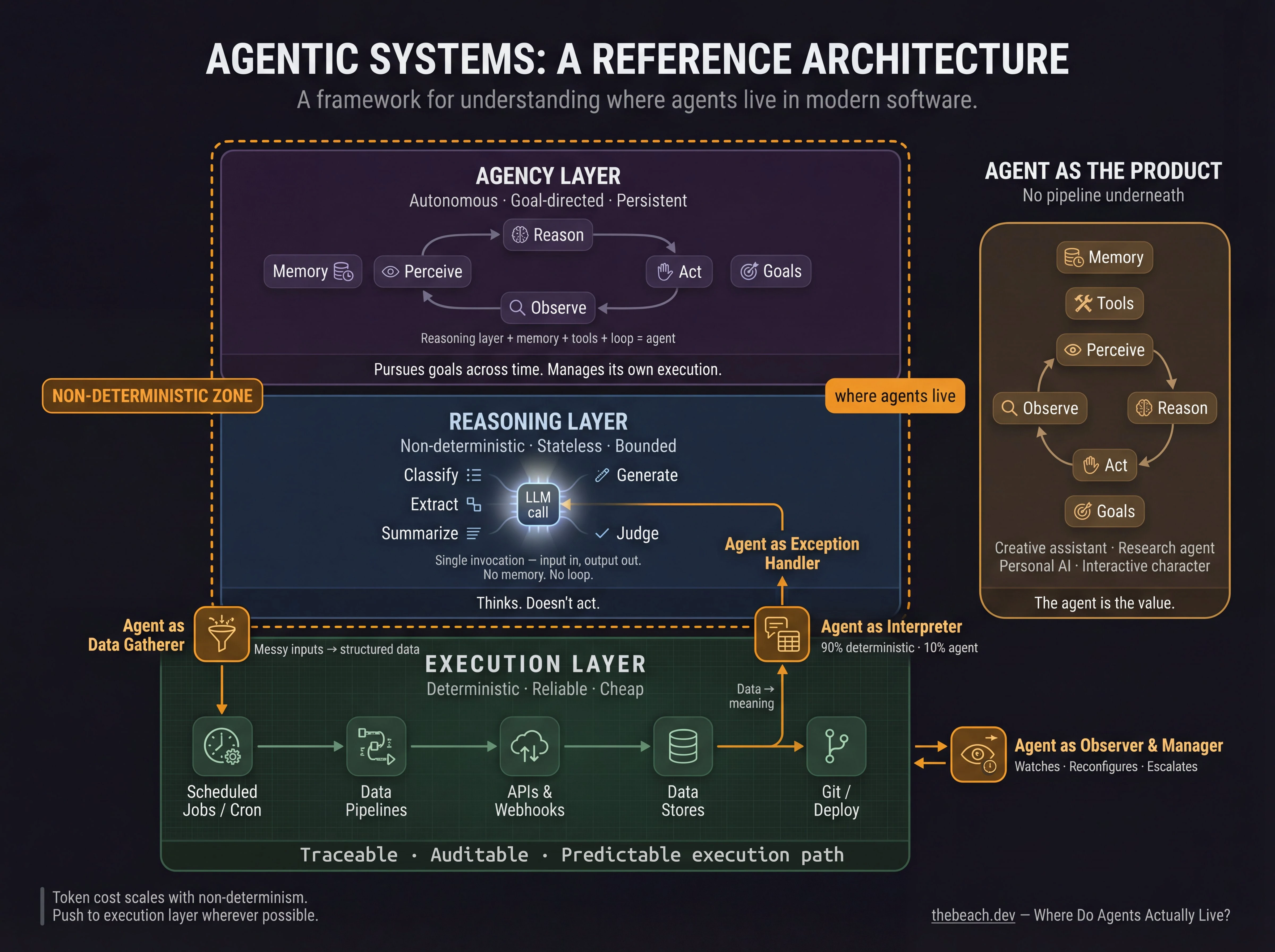
One Way to Think About It: Three Layers
One useful framing, and I’ll offer it as a starting point rather than a settled structure, is to think about agentic systems in three layers (architects always think in layers, it’s inevitable). A better model may emerge as the field matures, but this one could be helpful for reasoning about design decisions. Pun not intended.
The execution layer is where things actually happen. Code runs. APIs are called. Files are written. Cron jobs fire. This layer is deterministic by design, it does what it’s told, reliably and repeatably. Python code, a GitHub Actions workflow, a database query, a scheduled task. The execution layer doesn’t think… It executes. And crucially, whatever happens inside it, you can always explain what ran, in what order, and why.
The reasoning layer is where LLMs live. This layer handles the things that execution can’t, ambiguous inputs, unstructured language, judgment under uncertainty, creative generation. An LLM call to extract structured data from a scraped webpage. A prompt that asks whether a piece of content meets a quality threshold. A model generating a social media post from a set of facts. The reasoning layer thinks, but it doesn’t act, it produces outputs that other layers consume.
The agency layer is what makes a system agentic. An agent isn’t just an LLM call, it’s an LLM with memory, tools, and a loop. Perceive, reason, act, observe, repeat. The agency layer is where autonomous behavior emerges: where a system can pursue a goal across multiple steps, adapt when conditions change, and manage its own execution without a human in the loop for every decision.
As more systems are built with generative AI, language models, and reasoning, they will likely have all three. The question is how they’re connected, and that’s where the interesting design patterns live.
Five Ways Agents Inhabit Systems
Below are five patterns that I’ve seen, considered, or used myself for how the reasoning and agency layers can interact with the execution layer. These aren’t mutually exclusive, a single system could have multiple of these patterns at once, but they represent different design choices about where to put the agent and what role it plays. I don’t think this is an exhaustive list, or even necessarily correct, but it’s maybe a starting point for thinking about the design space.
Agent as Data Gatherer. The agent does the messy, ambiguous upstream work that deterministic code can’t handle, and hands off structured data to a pipeline that processes it reliably downstream.
AIToolz is built on this pattern. Every day, agents scrape YouTube videos and web articles, transcribe audio, and use a language model to identify and score mentions of AI tools. That’s the fuzzy, judgment-heavy part, deciding whether something is worth including, extracting structured attributes from unstructured text. Once that’s done, a deterministic pipeline takes over: validate, deduplicate, generate the page, run a QA pass, push to git, auto-deploy. The agent handles ambiguity. The pipeline handles reliability. Neither does the other’s job.
Agent as Observer and Manager. The agent watches over running systems, interprets their state, and intervenes when needed, reconfiguring, rescheduling, or escalating based on what it sees.
I run an OpenClaw instance on a DigitalOcean droplet that manages social media activity for Lorie Lowell, the AI persona behind the AIToolz podcast. The agent runs a set of cron jobs, posting, engaging, timing content, but what makes it genuinely agentic is that I can message it on Telegram and tell it to change what it’s doing. “Change evening post to 9pm.” “Approve posts 1 and 3.” “Start a thread about the latest Anthropic news.” It updates its own schedule and adjusts its behavior in response to natural language instructions. No code changes. No redeployment. The cron infrastructure stays deterministic; the agent manages it.
This is a meaningful distinction. Hard-coding scheduling logic means every change requires a developer. Putting an agent in the management layer means the system can be steered by whoever understands the goal, not just whoever can edit the config.
Agent as Interpreter. The deterministic pipeline produces data. The agent gives it meaning.
A portfolio tracker that parses brokerage statements, records holdings, and calculates performance is entirely deterministic, and should be. That precision is the point. But adding an LLM layer that can answer “what’s my sector concentration risk?” or “how would a rate increase affect this portfolio?” in plain language turns structured data into something you can actually reason with. The pipeline produces the numbers; the agent provides the analysis.
Agent as Exception Handler. The deterministic pipeline runs until it hits something it can’t resolve. Then it hands off to an agent.
This pattern is underused and underappreciated. Most pipelines today either fail hard on unexpected inputs or accumulate increasingly complex branching logic trying to anticipate every edge case. A cleaner approach is to let the pipeline handle the predictable 90% deterministically and route edge cases to an agent that can reason about them. The agent handles the ambiguity, returns a structured result, and the pipeline continues. The execution layer stays clean; the reasoning layer handles the exceptions.
Agent as the Product. Sometimes the agent isn’t supporting a workflow at all, it’s the thing itself.
A creative writing assistant. A coding partner. A research agent that synthesizes sources into a briefing. A character in an interactive story. A personal assistant that knows your context and helps you think. In these cases there’s no deterministic pipeline underneath, the agent is the value. The design challenge here is different: less about where to put the intelligence and more about how to give the agent the right context, tools, and constraints to be genuinely useful rather than just generative.
The Token Cost Is a Design Signal
One thing that rarely comes up in these conversations but matters practically: every LLM call costs tokens, and tokens have real costs in money, latency, and unpredictability.
Deterministic systems are cheap, fast, and scale linearly. An agent loop that calls an LLM at every step is expensive, slower, and harder to reason about at scale. This isn’t an argument against agents, it’s an argument for using them deliberately.
The discipline is: push everything that can be deterministic down to the execution layer. Reserve the reasoning and agency layers for the things that actually require them. An agent doing something a simple for-loop could handle is burning tokens on nothing. An agent doing genuine judgment work, interpreting ambiguity, managing complexity, operating in natural language, is earning its cost.
A signal could be that, when writing increasingly elaborate prompts to get an agent to do something very specific and repeatable, perhaps that task belongs in code, not in a prompt.
Toward a Reference Architecture
Pull all of this together and a rough reference architecture starts to emerge, rough being the operative word. This is a sketch, not a specification.
At the base, the execution layer: deterministic pipelines, scheduled jobs, APIs, data stores. Traceable, auditable, cheap to run. This is where things get done, and where you can always explain what happened.
In the middle, agents playing specific roles at the boundaries of that execution layer: feeding it clean data from messy inputs, managing and reconfiguring it in response to changing conditions, interpreting its outputs in plain language, handling the exceptions it can’t resolve on its own.
At the top, or standing somewhat apart, fully autonomous agents pursuing goals across longer time horizons, the OpenClaw instance, the research agent, the creative collaborator, operating with enough tools and memory to function independently.
The insight, such as it is: these aren’t competing paradigms. They’re different roles in the same system. The question for any given capability isn’t “should I use an agent or an automated workflow?” It’s “what role does intelligence play here, and where in the stack does it belong?”
Most of the time, the answer is that intelligence belongs at the seams, the places where ambiguity lives, where structure breaks down, where a human would otherwise have to make a judgment call. Everywhere else, code is still the right tool.
This is still early. The patterns I’ve described are ones I’ve arrived at through building, not through any established playbook, because there isn’t one yet. But I suspect the systems that age well will be the ones where the deterministic and the agentic are clearly separated, each doing what it’s actually good at, with explicit interfaces between them.
The failure mode to avoid is a system where everything is an agent because agents are exciting, where token costs spiral, debugging becomes impossible, and you can’t tell what the system will do next. The better outcome is one where the agent layer is precisely sized to the judgment required, and everything else is just code doing its job.
That line between “this needs intelligence” and “this just needs execution” is where the real design work happens.
Note that this article was co-written with Claude Sonnet 4.6. I made the first draft, then Claude helped edit. We spent hours going back and forth on the framing, the structure, the examples, the wording, and the overall flow. The result is a genuinely collaborative piece of human+AI thinking and writing. Images created with the help of Claude, Google Gemini (nano banana) and GOFG (good old-fashioned Gimp)